Chronicling America API in Python#
By Avery Fernandez and Jay Crawford
The Chronicling America API provides programmatic access to a vast collection of historic American newspapers, enabling researchers and developers to search, retrieve, and analyze digitized newspaper pages and metadata from the Library of Congress.
Please see the following resources for more information on API usage:
Documentation
Terms
Data Reuse
These recipe examples were tested on May 7, 2025.
Attribution: We thank Professor Jessica Kincaid (UA Libraries, Hoole Special Collections) for the use-cases. All data was collected from the Library of Congress, Chronicling America: Historic American Newspapers site, using the API.
Note that the data from the Alabama state intelligencer, The age-herald, and the Birmingham age-herald were contributed to Chronicling America by The University of Alabama Libraries: https://chroniclingamerica.loc.gov/awardees/au/
Setup#
The following external libraries need to be installed into your environment to run the code examples in this tutorial:
We import the libraries used in this tutorial below:
import requests
import matplotlib.pyplot as plt
from pprint import pprint
import re
1. Retrive a Record from its LCCN#
The Chronicling America API identifies newspapers and other records using LCCNs. We can query the API once we have the LCCN for the newspaper and even ask for particular issues and editions. For example, the following link lists newspapers published in the state of Alabama, from which the LCCN can be obtained: Chronicling America: Alabama Newspapers.
Here is an example with the Alabama State Intelligencer:
BASE_URL = "https://chroniclingamerica.loc.gov"
endpoint = "lccn"
lccn = "sn84021903"
try:
response = requests.get(f"{BASE_URL}/{endpoint}/{lccn}.json")
# Raise an error for bad responses
response.raise_for_status()
data = response.json()
pprint(data, depth=1)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
data = None
{'end_year': '183?',
'issues': [...],
'lccn': 'sn84021903',
'name': 'Alabama state intelligencer. [volume]',
'place': [...],
'place_of_publication': 'Tuscaloosa, Ala.',
'publisher': "M'Guire, Henry & M'Guire",
'start_year': '1829',
'subject': [...],
'url': 'https://chroniclingamerica.loc.gov/lccn/sn84021903.json'}
Indexing into the json output allows data to be extracted using key names as demonstrated below:
if data:
pprint(data["name"])
'Alabama state intelligencer. [volume]'
if data:
pprint(data["publisher"])
"M'Guire, Henry & M'Guire"
Moving on to another publication, we can get the 4th page (seq-4) of the The Ocala evening star newspaper published on July 29th, 1897.
endpoint = "lccn"
lccn = "sn84027621"
date = "1897-07-29"
edition = "ed-1"
page = "seq-4"
try:
response = requests.get(f"{BASE_URL}/{endpoint}/{lccn}/{date}/{edition}/{page}.json")
# Raise an error for bad responses
response.raise_for_status()
data = response.json()
pprint(data, depth=1)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
data = None
{'issue': {...},
'jp2': 'https://chroniclingamerica.loc.gov/lccn/sn84027621/1897-07-29/ed-1/seq-4.jp2',
'ocr': 'https://chroniclingamerica.loc.gov/lccn/sn84027621/1897-07-29/ed-1/seq-4/ocr.xml',
'pdf': 'https://chroniclingamerica.loc.gov/lccn/sn84027621/1897-07-29/ed-1/seq-4.pdf',
'sequence': 4,
'text': 'https://chroniclingamerica.loc.gov/lccn/sn84027621/1897-07-29/ed-1/seq-4/ocr.txt',
'title': {...}}
# Download and save the PDF
if data:
# Get the PDF URL from the JSON response
pdf_url = data['pdf']
# Download the PDF file
try:
pdf_response = requests.get(pdf_url, allow_redirects=True)
# Save the PDF file to disk
with open(f"{lccn}_{date}_{edition}_{page}.pdf", 'wb') as pdf_file:
pdf_file.write(pdf_response.content)
except requests.exceptions.RequestException as e:
print(f"An error occurred while downloading the PDF: {e}")
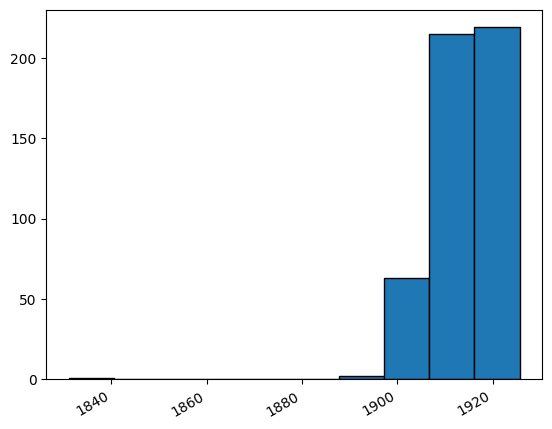
2. Frequency of “University of Alabama” Mentions#
The URL below limits to searching newspapers in the state of Alabama and provides 500 results of “University of Alabama” mentions. Note that phrases can be searched by putting them inside parentheses for the query.
endpoint = "search/pages/results"
params = {
"state": "Alabama",
"proxtext": "(University of Alabama)",
"rows": 500,
"format": "json"
}
try:
response = requests.get(f"{BASE_URL}/{endpoint}", params=params)
# Raise an error for bad responses
response.raise_for_status()
data = response.json()
pprint(data["items"][0], depth=1)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
data = None
{'alt_title': [...],
'batch': 'au_foster_ver01',
'city': [...],
'country': 'Alabama',
'county': [...],
'date': '19240713',
'edition': None,
'edition_label': '',
'end_year': 1950,
'frequency': 'Daily',
'id': '/lccn/sn85038485/1924-07-13/ed-1/seq-48/',
'language': [...],
'lccn': 'sn85038485',
'note': [...],
'ocr_eng': 'canes at the University .of Alabama\n'
'MORGAN HALL -\n'
'SMITH HALL\n'
"' hi i ..mil w i 1»..IIgylUjAiU. '. n\n"
'jjiIi\n'
'(ARCHITECTS* MODEL)\n'
'COMER. HALli\n'
'MINING\n'
'••tSgSB?\n'
"* i v' y -4\n"
"■Si ' 3>\n"
'A GLIMP9E OF FRATERNITY ROW\n'
'THE GYMNASIUM\n'
'Tuscaloosa, Alabama\n'
'ADV.',
'page': '8',
'place': [...],
'place_of_publication': 'Birmingham, Ala.',
'publisher': 'Age-Herald Co.',
'section_label': 'Tuscaloosa Section',
'sequence': 48,
'start_year': 1902,
'state': [...],
'subject': [...],
'title': 'The Birmingham age-herald. [volume]',
'title_normal': 'birmingham age-herald.',
'type': 'page',
'url': 'https://chroniclingamerica.loc.gov/lccn/sn85038485/1924-07-13/ed-1/seq-48.json'}
if data:
print(len(data["items"]))
500
# Create a list of dates from each item record
dates = []
if data:
for item in data["items"]:
dates.append(item["date"])
# Show first 10
pprint(dates[:10])
['19240713',
'19180818',
'19160716',
'19240224',
'19160806',
'19130618',
'19110815',
'19241029',
'19240217',
'19150801']
from datetime import datetime
converted_dates = [datetime.strptime(date, '%Y%m%d') for date in dates]
# Print first 10 dates
converted_dates[0:10]
[datetime.datetime(1924, 7, 13, 0, 0),
datetime.datetime(1918, 8, 18, 0, 0),
datetime.datetime(1916, 7, 16, 0, 0),
datetime.datetime(1924, 2, 24, 0, 0),
datetime.datetime(1916, 8, 6, 0, 0),
datetime.datetime(1913, 6, 18, 0, 0),
datetime.datetime(1911, 8, 15, 0, 0),
datetime.datetime(1924, 10, 29, 0, 0),
datetime.datetime(1924, 2, 17, 0, 0),
datetime.datetime(1915, 8, 1, 0, 0)]
# Plot the number of records and dates
fig, ax = plt.subplots()
plt.hist(converted_dates, bins=10,edgecolor='black')
# Rotates and right-aligns the x labels so they don't crowd each other.
for label in ax.get_xticklabels(which='major'):
label.set(rotation=30, horizontalalignment='right')
plt.show()
3. Sunday Comic Titles in the Age-Herald#
The Age - Herald published comics every Sunday, we will try to extract the titles of those published on page 15 of the 17th October 1897 edition.
endpoint = "lccn"
lccn = "sn83045462"
date = "1927-06-01"
edition = "ed-1"
page = "seq-14"
try:
response = requests.get(f"{BASE_URL}/{endpoint}/{lccn}/{date}/{edition}/{page}/ocr.txt")
# Raise an error for bad responses
response.raise_for_status()
data = response.text
# Show first 500 characters
print(data[:500])
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
data = None
14
i BUYING CONTINUES
| IN STOCK MARKET
Most Interest Is Taken in
( U. S. Steel TodayâSell
at New Top.
BY GEORKK T. HLGIIES.
Special Dispatch to The Star.
NEW YORK. June 1. âIgnoring: en
tirely the increase in brokersâ loans,
which brought the total up to the
highest of the year, the stock market
started in today with the buying
movement in the favored rails and
industrials showing no signs of a let
up. Time money was a shade firmer,
but call funds renewed at 4% per cent
unchanged, and Wal
if data:
# Split the OCR text into lines
for line in data.split("\n"):
# Replace all non-uppercase letters with spaces
cleaned_line = re.sub(r"[^A-Z]+", ' ', line)
# Calculate the number of letters and spaces in the cleaned line
num_spaces = cleaned_line.count(" ")
num_letters = len(cleaned_line) - num_spaces
# Check if at least 75% of the characters in the line are letters
if len(cleaned_line) > 0 and (num_letters / len(cleaned_line)) >= 0.75:
# Print the cleaned line if it meets the criteria
print(cleaned_line)
BUYING CONTINUES
IN STOCK MARKET
BY GEORKK T HLGIIES
DIVIDEND OMITTED
FINANCIAL
I NEW YORK STOCK EXCHANGE
DROW
THE EVENING STAR WASHINGTON I C WEDNESDAY JUNE T
MS PASSM
PEPCO PREFERRED
AT NEW TOP MARK
BY EDWARD C STONE
COTTON RECOVERS
AFTER EARLY DROP
POTATOES STRONG
NEW YORK MARKETS
RUBBER STEADY
SHORT TERM SECURITIES
DIVIDENDS
NEW YORK MAIN
COMMODITY NEWS
WIRED STAR FROM
ENTIRE COUNTRY
NEW ORLEANS T U
PORTLAND O O
I YOUNGSTOWN F
NOTED BANKER DIES
DIVIDEND DECLARED
CITIZENS BANK BUILDING WOODWARD BUILDING
BALTIMORE MD WASHINGTON D C
JOHN JOY EDSON P WALTER S PRATT J S
O YEAR COMPLETED
S YSTEMATICALLY
LINCOLN NATIONAL BANK
THE FRANKLIN NATIONAL BANK
BANK OF COMMERCE AND SAVINGS
SECURITY SAVINGS AND COMMERCIAL BANK
DISTRICT NATIONAL BANK
AMERICAN SECURITY AND TRUST COMPANY
UNITED STATES SAVINGS BANK
SEVENTH STREET SAVINGS BANK
THE RIGGS NATIONAL BANK
MOUNT VERNON SAVINGS BANK
THE WASHINGTON LOAN AND TRUST COMPANY
FINANCIAL
CREDIT RENEWED
WOOL PRICES STEADY
PRICES ON PARIS BOURSE
BUTTER UNSETTLED
TREASURY CERTIFICATES
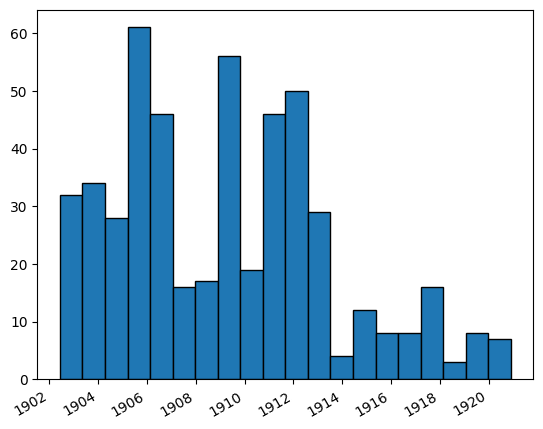
4. Industrialization Keywords Frequency in the Birmingham Age-Herald#
We will try to obtain the frequency of “Iron” on the front pages of the Birmingham Age-Herald newspapers from the year 1900 to 1920. (limited to first 500 rows for testing here)
endpoint = "search/pages/results"
params = {
# Search for Alabama newspapers
"state": "Alabama",
"lccn": "sn85038485",
# Filter by date range
# 1900 to 1920
"dateFilterType": "yearRange",
"date1": 1900,
"date2": 1920,
# Filter by sequence number
# 1 is the first page of the newspaper
"sequence": 1,
# Filter by text "Iron"
"andtext": "Iron",
"rows": 500,
"searchType": "advanced",
"format": "json"
}
try:
response = requests.get(f"{BASE_URL}/{endpoint}", params=params)
# Raise an error for bad responses
response.raise_for_status()
data = response.json()
pprint(data["items"][0], depth=1)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
data = None
{'alt_title': [...],
'batch': 'au_flagg_ver01',
'city': [...],
'country': 'Alabama',
'county': [...],
'date': '19090113',
'edition': None,
'edition_label': '',
'end_year': 1950,
'frequency': 'Daily',
'id': '/lccn/sn85038485/1909-01-13/ed-1/seq-1/',
'language': [...],
'lccn': 'sn85038485',
'note': [...],
'ocr_eng': 'THE BIRMINGHAM AGE-HERALD.\n'
'VOLUME XXXVIH. , BIRMINGHAM, ALABAMA, WEDNESDAY, JANUARY 13, '
'1909. 12 PAGES. NUMBER 252\n'
'REVENUE TARIFF\n'
'IS UNDERWOOD’S\n'
'SCHEME ON IRON\n'
'Alabama Congressman Fires\n'
'Some Plain Facts on\n'
'“ tbe Tariff\n'
'GREAT DEMAND FOR PIG\n'
'IRON DURING YEAR 190/\n'
'Congressman Underwood Explains His\n'
', Attitude Upon Steel and Iron Sub\n'
'jects and Compares Cost\n'
'of Production.\n'
'Washington, January 12.—(Special.)—\n'
'Representative Underwood o£ Alabama\n'
'stated today that he had read an account\n'
'of a meeting of the Commercial club of\n'
'Birmingham in which he was criticised\n'
'for not being in favor of tbe tariff of\n'
'*4 per ton on pig iron and In which those\n'
'who asserted this fact seem to come to\n'
'this conclusion because he had cross-ex\n'
'amined certain witnesses appearing before\n'
'• the ways and means committee.\n'
'Mr. Underwood said he had never been\n'
'In favor of a protective tariff for pro\n'
"tection's sake, but had always conformed\n"
'tu tlie principles of his parly and ad\n'
'vocated a tariff for revenue, believing that\n'
'the Incidental protection that would arise\n'
'from a tariff for revenue would foster the\n'
'legitimate business of the country. He\n'
'slated that the ways and means commit\n'
'tee was endeavoring to write a tariff bill\n'
'that would produce sufficient revenue to\n'
'run the government and wipe out the\n'
'very large deficit that now exiBts; that\n'
'the present duty on pig iron was practi\n'
'cally prohibitive and in order tliat some\n'
'revenue could be raised, a reduction\n'
'would be necessary but there was no ue\n'
'i sire on the «part of any of the members\n'
'of the ways and means committee to do\n'
'anything that would seriously Injure the\n'
'business of the country; that there was\n'
'more pig iron imported into the united\n'
'States in the year 1907 than the entire\n'
'amount imported for the three preced\n'
'ing years, and that this was due to the\n'
'high price and great demand for pig iron\n'
'in that year; that the total importations\n'
'amounted to 306,000 tons and the total pro\n'
'duction of pig iron in the Urn ted States\n'
'amounted to 26,307.000 tons, which showed\n'
'that the total importations into this conn -\n'
'try were less than cent of the\n'
'production for that year, and less than\n'
'1 per cent for the preceding years.\n'
'No Evidence Shown.\n'
'Mr Underwood said that there was no\n'
"' evidence before the ways and means com\n"
'mittee that pig iron was made anywhere\n'
'else in the world at a less cost than\n'
'*8 50 and that the average cost in Ger\n'
'many and England was *11 per ton; that\n'
'average freight rates from the foreign\n'
'furnaces to New York was *2.So, which\n'
'would lay the foreign iron in New York\n'
'harbor at *13.35. To this it would be\n'
'necessary to add the cost of loading on\n'
'the oars and hauling it to the Amer\n'
'ican foundry for consumption, that *1 a\n'
'ton added for this purpose would cer\n'
'tninlv be below the average cost which\n'
'would make the cost price of foreign pig\n'
'< Iron laid down at the American foundry,\n'
'in the neighborhood of *15; that the got -\n'
'eminent reports show that the value of\n'
'foreign pig iron was *15.99 for 1907, *15.20\n'
'for 1906. *14.31 for 1905 and *16.12 for 1904,\n'
'or an average of *15.40 for the four years,\n'
'to which add $2.85 freight from the foreign\n'
'furnace to the seaports. *1 for loading and\n'
'domestic freight, which made th® c°™Pe\n'
'tition price in the eastern market *19.2»\n'
'a ton exclusive of any tariff duty what\n'
'ever He said that the average cost\n'
'of nig iron in the Birmingham district\n'
'was *10 per ton. the freight rate to New\n'
'York being *4.26, it would lay the Bir\n'
'mingham iron down In the foundries on\n'
'the seaboard at about *14.25 or under *15\n'
'per ton.\n'
'Cost of Iron.\n'
'In a paper prepared for tbe British In\n'
'stitute Of Civil Engineers, by the Messrs.\n'
'Head and afterwards quoted with ap\n'
'proval by J. S. Jeans, secretary of the\n'
'British Iron Trade association, the cost\n'
'of a ton of pig iron at Middlesborough,\n'
'England, was given as 52 shillings 2\n'
'pence or *12.70 and these furnaces are\n'
'certainly a fair average of the British pro\n'
'duction.\n'
'In considering the question of compe\n'
'tition from abroad, It should be borne\n'
'In mind, Mr. Underwood suggested, that\n'
'the cheapest iron produced abroad did not\n'
'come In competition with tbe American\n'
'furnaces, for no man sought a foreign\n'
'market for his products where he could\n'
'obtain domestic market at home, and the\n'
'cheaper iron always sold in the home\n'
'markets and the higher priced Iron was\n'
'forced to find other markets for its sale;\n'
'so that If there was no duty on pi--- r\n'
'at all, the difference In the cost of i •\n'
'auction, with freight added, between t no\n'
'Birmingham district and foreign iron\n'
'would not be great in the eastern mar\n'
'kets.\n'
'High Freight Rates.\n'
'Of course In the southern and western\n'
'markets there would be no chance for\n'
'" foreign competition whatever, as tbe\n'
'I freight rates entirely exclude the foreign\n'
'Iron from these markets under any cir\n'
'cumstances. He said that some of the\n'
'I furnaces in the Birmingham district were\n'
'making pig iron at about *9 per ton, so\n'
'far as his information went, but *10 on\n'
'an average was probably a fairer esti\n'
'mate. That, although these figures might\n'
'not justify a duty on pig iron from a\n'
'protective tariff standpoint, nevertheless\n'
'he was In favor of levying a duty on\n'
'pig iron and the other Iron and steel\n'
'products for the purpose of raising rev\n'
'enue; that there was no schedule In the\n'
'entire tariff list that more equitably dis\n'
'tributed the burden of taxation than did\n'
'V’ the duty levied on the importation of iron\n'
'and steel products; that a tax on articles\n'
'consumed by the people such as sugar\n'
'and clothing would more nearly be a\n'
'per capita tax, each man paying not In\n'
'proportion to his wealth, but In propor\n'
'tion to numbers, whereas a tax levied\n'
'on Iron and steel products was more near\n'
'ly distributed In proportion to the wealth\n'
'of the country.\n'
'The poor man who had little property\n'
'for tlio government to protect paid the\n'
'tr\\ on his plow or his cooking stove,\n'
'wWeas the rich man paid Immensely\n'
'r,ore on the steel frame building, the au\n'
'tomobile or for great machinery used in\n'
'his factories, railroad iron and other com\n'
'*’ modlties of like nature; thus making the\n'
'burden of a tax levied on Iron and steel\n'
'more a tax on wealth than on poverty,\n'
'■which undoubtedly wae Just and for this\n'
'reason he was now and had always been\n'
'I I\n'
'THE COMMITTEE\n'
"Hitchcock's Successor Is to\n"
'Be Former Secretary\n'
'TUFT GOING TO ATLANTA\n'
'The President-Elect Will Attend the\n'
"'Possum Supper and Then Go Back\n"
'To Atlanta To Be the\n'
'Guest at Reception.\n'
'Augusta, January 12.—Exact precedent\n'
'is to be followed In the succession of\n'
'Frank H. Hitchcock, as chairman of the\n'
'republican national committee. This prece\n'
'dent will place William Hayward, secre\n'
'tary of the committee, at its head until\n'
'the committee elects a chairman at its\n'
'meeting to be held four years hence, in\n'
'December preceding the next national\n'
'convention.\n'
'When Chairman Cortelyou relinquished\n'
'his position as the head of the commit\n'
'tee some months after he became Post\n'
'master General, Harry S. N^w, its secre\n'
'tary, was made vice chairman, and con\n'
'ducted the affairs of the committee, which\n'
'j Is practically dormant prior to the De\n'
'i cember meeting, called to make the ar\n'
'i rangements for the election of delegates\n'
'I to the national convention.\n'
'I That Secretary Hayward will have\n'
'I charge of the affairs of the committee\n'
'j when they are relinquished by Mr. Hitch\n'
'I cock was ascertained here from most re\n'
'liable authority today, although no official\n'
'statement on the subject is deemed neces\n'
'sary at this time. The rules and prac\n'
'tice of the committee make it the duty\n'
'of the chairman to provide his successor\n'
'by appointment.\n'
'The insistence of Atlanta to have the\n'
'President-elect for two evenings resulted\n'
'today in his consent to return to that\n'
'city Saturday afternoon to be present at\n'
'a reception to be tendered him by the\n'
'Capital City club Saturday night. Mr.\n'
'Taft will go to Atlanta Friday morning,\n'
'be the guest at the famous ’pdBsiim sup\n'
'per, for which preparations have been\n'
'in active progress for several weeks.\n'
'He will leave Atlanta Saturday for\n'
'Athens, where he will be formally re\n'
'ceived and escorted to the state univer\n'
'sity for an address. He will then return\n'
'to Atlanta and after the reception begin\n'
'his Journey back to Augusta, where he\n'
'will arrive Sunday morning.\n'
'Mr. Taft abandoned his golf game this\n'
'morning that he might attend the meet\n'
'ing of the Richmond County Bar associa\n'
'tion. He made no speech to the lawyers,\n'
'but evidenced great Interest in the pro\n'
'ceedings which were chiefly the reading\n'
'of a lengthy paper by former Judge An\n'
'drew J. Cobb of the state supreme court\n'
'on the Jury system In Georgia. The golf\n'
'game was played this afternoon between\n'
'showers. The change in the tariff was\n'
'discussed today with the President-elect\n'
'by a Mr. Gregory, a manufacturer and\n'
'exporter of machinery of New York. J.\n'
'H. White of Louisiana was received. He\n'
'bore a letter of Introduction from Pearl\n'
'Wright, national republican committee\n'
'man from that state. Mr. White made a\n'
'social call.\n'
'Mrs. WTlliam H. Taft will leave here\n'
'Thursday for New Haven, Conn., where\n'
'she goes to attend a class function of\n'
'her son, Robert, at Tale. She will re\n'
'turn In time to sail with the President\n'
'elect for Panama, having determined to\n'
'make the trip to the isthmus.\n'
'The Taft family were dinner guests to\n'
'night of Boykin Wright, a prominent at\n'
'torney of this city.\n'
'in favor of levying a fair revenue rate on\n'
'iron and steel commodities, including pig\n'
'Iron, imported into this country.\n'
'Fair Revenue.\n'
'Mr. Underwood stated that as a member\n'
'of the ways and means committee it\n'
'would not be proper for him to state at\n'
'this time as to what he thought a fair\n'
'revenue rate would be. He must neces\n'
'sarily consult his colleagues on the com\n'
'mittee and endeavor to reach a verdict\n'
'with them, but he believed that a fair\n'
'revenue rate would be adopted. The ways\n'
'and means committee must of necessity\n'
'reach their conclusions, not from expres\n'
'sions of opinion, but upon the evidence\n'
'brought before them at their hearings;\n'
'that the committee had Invited all tlie\n'
'iron and steel producers in the country\n'
'l to appear before the committee and pre\n'
'sent their testimony and express their\n'
'wishes In reference to the matter; that\n'
'this invitation included the iron and steel\n'
'musters of the Birmingham district; that\n'
'he had personally Invited some of the\n'
'iron and steel men to appear before the\n'
'committee and regretted that not a single\n'
'man Interested In the great iron and steel\n'
'development of the Birmingham district\n'
'saw proper to appear before the commit\n'
'tee and advise it in reference to the\n'
'situation. He said the hearings are now\n'
'closed but if the iron and steel men of\n'
'Birmingham desire a hearing that lie\n'
'would make a personal request of the\n'
'chairman and endeavor to secure one for\n'
'them even at this late date. That ns\n'
'the facts stated at the meeting before\n'
'the Commercial club did not agree with\n'
'the testimony before the ways and means\n'
'committee, he thought that it was only\n'
'fair for those who asserted them to pro\n'
'duce them as lawful evidence before the\n'
'committee if they desired them to be\n'
'acted upon. He said that In examining\n'
'the witnesses before the committee he\n'
'did not examine the witnesses In refer\n'
'ence to the Iron and steel schedules any\n'
'more or less strenuously than he did\n'
'those who came to represent other sched\n'
'ules and that he did this with no Inten\n'
'tion of expressing an opinion at that time,\n'
'but merely to ascertain and disclose the\n'
'entire truth in reference to the matters\n'
'that came before the committee for their\n'
'decision..\n'
'Mr. Underwood added that he regarded\n'
'his position on the ways and means com\n'
'mittee, as that of a Judge to render a\n'
'fair verdict to the people of the country,\n'
'the government and the great productive\n'
'interests of the nation, rather than that\n'
'of a partisan to advocate the cause of\n'
'special interests. That the greatest fac\n'
'tor in the upbuilding of the city of Bir\n'
'mingham had been the fact that its fur\n'
'naces could make the cheapest pig iron in\n'
'America and no beneflt will come from\n'
'an effort to disguise this fact.\n'
'MORE THAN ONE HUNDRED\n'
'HUMAN LIVES ARE LOST IN\n'
'FEARFUL MINE EXPLOSION\n'
"HUNS' COUNSEL\n"
'MAKES CHARGES\n'
'Attorney McIntyre Says State\n'
'Witnesses Were Rehearsed\n'
'CALLS TESTIMONY FALSE\n'
'Mr. McIntyre Declares That Yacht\n'
'Club Members Manufactured Their\n'
'Testimony To Suit the\n'
'Occasion.\n'
'Flushing, N. T., January 12.—Charges\n'
'that the testimony of members of the\n'
'Bay-side Yacht club were manufactured\n'
'and that witnesses were withdrawn from\n'
'the stand because their testimony was\n'
'not sufficiently rehearsed were made by i\n'
'Attc\n'
'the j\n'
'kins Halns. Mr. Mcltnyre had not fin- !\n'
'Ished his closing address when adjourn\n'
'ment was taken. Counsel spent over five\n'
'hours today in reviewing the evidence In\n'
'the case and pointing out discrepancies\n'
'which, the lawyer asserted, showed that\n'
'much of the testimony of the state had\n'
'been rehearsed In an instruction school.\n'
'Mr. McIntyre declared that much of the\n'
'testimony of Mrs. William K. Annis,\n'
'whoso husband was shot and killed by\n'
'Capt. Peter C. Hains, Jr., was “mani\n'
'festly false,” and that she had been taken\n'
'from the witness stand when It was seen\n'
'that her story had not been sufficiently\n'
'rehearsed.\n'
"During the defendant's closing Mr. Mc\n"
'Intyre and Prosecutor Darrin had verbal\n'
'clashes which occasionally punctuated\n'
"Mr. McIntyre's dramatic recital.\n"
'Justice Crane Informed Mr. McIntyre\n'
'that he must conclude his address at\n'
'noon tomorrow, when the state will begin\n'
'to sum up. He said the case must go\n'
'to the jury Thursday.\n'
'INDEX OF TODAY’S NEWS\n'
'Prge 1.\n'
'Fearful mine explosion in West Virginia.\n'
'Tennessee senate passes prohibition bill.\n'
'Congressman Und>rwood explains his\n'
'position on tariff.\n'
'Bonaparte replies to Bon Tillman.\n'
'Hayward to succeed Hitchcock.\n'
'Counsel for Hains makes serious\n'
'charges.\n'
'Newspaper men found guilty of libel.\n'
'Page 2.\n'
'Negroes badly wanted in Ensley.\n'
"Work done by the Farmers' union.\n"
'Page 3.\n'
'Steel cars to be repaired.\n'
'Hitch is found In game laws.\n'
'Investigation has been granted.\n'
'Page 4.\n'
'Editorial comment.\n'
'Page 5.\n'
'Presiding elders of North Alabama con\n'
'ference meet in Birmingham.\n'
'Mountain Terrace election held valid.\n'
'Italian relief fund nearly $3000.\n'
'Special committee reports legislature\n'
'has power to create Greater Birmingham.\n'
'Birmingham banks hold annual meet\n'
'ings.\n'
"Cobbs' Coosa plan Indorsed.\n"
'Page 7.\n'
'Birmingham society.\n'
'Feminine fancies, by Dolly Dalrymple.\n'
'Page 8.\n'
'Foraker attacks the President.\n'
'Bessemer delighted at prospect of new\n'
'industries.\n'
'Page 10.\n'
'Tillman replies to Bonaparte.\n'
'Page 11\n'
'Stock market Is steady.\n'
'Cotton declines a few points.\n'
'Wheat makes a sharp decline.\n'
'Page 12.\n'
'Baseball association meets.\n'
'Force of tire Explosion is\n'
'Greater Than Ever Known lo\n'
'the Mining District of\n'
'West Virginia\n'
'■ <\n'
'MEN AND MACHINERY\n'
'ARE BLOWN FROM MINE\n'
'LIKE LEAVES OF TRESE\n'
'It Is Believed That Not One of the\n'
'Workers In the Ill-Fated Mine\n'
'Escaped Alive, and the\n'
'Scenes of Sorrow\n'
'Are Pitiful.\n'
'Bluefield, W. Va„ January 12.—Again !\n'
'the earth trembled today and that un- [\n'
'known gaseous substance in which there ;\n'
'is more deadly energy and destruction to\n'
'the atom than in tons of dynamite let go\n'
'in the mines of the Lick Branch col\n'
'liery and snuffed out more than 100 lives.\n'
'It was in the same mines where, two\n'
'weeks ago to a day, BO miners were killed\n'
'by a similar explosion.\n'
'In the quiet of the early morning there J\n'
'came, like the sound of thunder, a mighty\n'
'rumbling in the earth which reverberated\n'
'along the miles of corridors and air pas- j\n'
'sages crowded with those who worked !\n'
'there. Above the tons of earth and stone {\n'
'that lay between the workings and the\n'
"mountain's crown giant trees quivered\n"
'from the force of the concussion and from I\n'
"the mine's mouth the forces of the earth,\n"
'set free, belched forth a cloud of flame, |\n'
'soot, dust and debris, heavy timbers, |\n'
'broken mine cars, and even a massive\n'
'motor, used to haul the heavy-laden cars\n'
'from the depth. i\n'
'Scarcely had the detonation died away i\n'
'before a throng of terrorized women and !\n'
'children rushed to the mine mouth and !\n'
'Implored those there to allow them to\n'
'aid in the effort to save some of their\n'
'loved ones who might still be alive within.\n'
'Mine Foreman Bowers, who was near the\n'
'entrance, was blown from his feet but i\n'
'managed to crawl out safely, as did also j\n'
'Robert Smith a miner.\n'
'Rescuers Driven Back.\n'
'With the foreman was a miner named j\n'
'Holliday and he, too, was blown over. 1\n'
'A rescue party, organized on the moment, !\n'
'rushed into the smoking mines and tried\n'
'to rescue him. They were driven back !\n'
'by the fumes of the after gases and were ,\n'
'compelled to leave him to his fate.\n'
'A train was rushed from this city to\n'
'the scene of the disaster, some 26 miles\n'
'away, carrying brattlclng and other ma\n'
'terial to be used in the work of explora\n'
'tion and rescue.\n'
'There are more than 100 men in the sec\n'
'tion of the mine affected. The debris from\n'
'the explosion of two weeks ago had not\n'
'been cleared away and 20 men were en\n'
'gaged in this work. Nineteen contract\n'
'miners with their crews were at work\n'
'in a new entry and it Is feared that all\n'
'of these men were lost.\n'
'The explosion was In a different part\n'
'of the mine from that of two weeks ago.\n'
'Since that catastrophe the mine has been\n'
'inspected by government officials and by\n'
'the most experienced mine men in the\n'
"'/-^[tOT?W*roirPAGB^2!r ”\n"
'GUILTY^ OF LIBEL\n'
'John D. Rockefeller, Jr., Wins\n'
'Suit Against Hearst\n'
'PAROLED WITH COUNSEL\n'
'Carvalho, Merrill and Clark Are the\n'
'Convicted Ones and Defendants\n'
'Have Instituted Suit of\n'
'Habeas Corpus.\n'
'New York, January 12.—On the ground\n'
'that the publication of their names as the\n'
'responsible heads of the Star Publishing\n'
'company, which publishes William R.\n'
'Hearst’s New York American, made them\n'
'personally liable for libelous matter ap\n'
'pearing in that newspaper, Magistrate\n'
'Moss today found S. S. Carvalho, Brad\n'
'ford Merrill and Edward S. Clark guilty\n'
'of criminally libelling John D. Rockefeller,\n'
'Jr., and technically committed them to\n'
'the Tombs prison. * •\n'
'In notice that the defendants would ap\n'
'ply for a writ of habeas corpus in order\n'
'to test the validity of the law under\n'
'which they had been sentenced, the mag\n'
'istrate allowed them to remain in the\n'
'private reception room of the prison while\n'
'their counsel, Clarence J. Shearn, went\n'
'before Justice Davis in the supreme court\n'
'and obtained the writ.\n'
'Upon the granting of the writ. Messrs.\n'
'Carvalho. Merrill and Clark were paroled\n'
'in the custody of their counsel until\n'
'Thursday morning, when argument on the\n'
'writ will be heard.\n'
'The offenses for which Messrs. Carval\n'
'ho. Merrill and Clark were found guilty\n'
'of criminal libel was the publication in the\n'
'American of an article charging Mr.\n'
'Rockefeller with having been instru\n'
'mental In instituting a system of peon\n'
'age by a certain breakfast food com\n'
'pany in Illinois. Mr. Rockefeller him\n'
'self took the stand to testify in the case\n'
'and refused to withdraw the charge even\n'
'after the newspaper had printed a retrac\n'
'tion.\n'
'ANOTHER LETTER\n'
'FROM CARMICHAEL\n'
'Wellsburg, W. Va„ January 12.—The\n'
'Rev. John Haviland Carmichael, who\n'
'ended his life In Carthage, Ills., while\n'
'the agencies of the law were searching\n'
'the country for him in connection with\n'
'the murder of Gideon Browning, in the\n'
'little church at Rattle Run, Mich., shortly\n'
'before committing suicide wrote his\n'
'brother, M. C. Carmichael, of this place,\n'
'confessing to the Michigan homicide. The\n'
'letter came today. It is in part as fol\n'
'lows:\n'
'“Cartilage. 111.. January 9, 1909.\n'
'“M. C. Carmichael, Wellsburg, W. Va.:\n'
'“Dear Brother—No doubt you have\n'
'heard of the horrible tragedy of which I\n'
'have been guilty. 1 cannot tell you how\n'
'I am suffering now on account of it. I\n'
'know that I did the deed, but I hardly\n'
'know liow, or why, only that Browning\n'
'had such a hypnotic power over me that\n'
'It gave me tile horrors.\n'
'"I shall soon deliver myself to the state\n'
'authorities or to the Judge Eternal. I\n'
"can't stand tills being hunted down. I\n"
'am now in a uuiet place, where they may\n'
'not find me for a long time, but my con\n'
'science Is here, and hell Itself can be but\n'
'little more fiery.\n'
'“1 am sorry that 1 have so shocked\n'
'you all. but being sorry does not make\n'
'amends. Goodbye and Just pity me. be\n'
'cause 1 am your brother. J. H. C.”\n'
'Two brothers of the dead minister live\n'
'here, ami their families are among th#\n'
'most prominent In this section.\n'
'SOLAR PLEXUS IS\n'
'GIVEN TO LIQUOR\n'
'BY LEGISLATORS\n'
'WARM REPLY IS\n'
'MADE TO TILLMAN\n'
'Attorney General Bonaparte\n'
'Makes Statement\n'
'OREGON LAND DEAL FIGURES\n'
'Bonaparte Says He Furnished In\n'
'formation to Tillman About the\n'
'Lands—Senator Never\n'
'Spoke of Buying.\n'
'Washington, January 12.—Attorney\n'
'General Bonaparte tonight issued a\n'
'statement replying to that part of\n'
'the speech of Senator Tillman deliv\n'
'ered yesterday in which the senator\n'
'declared that the resolution in regard\n'
'to the Oregon land grants, introduced\n'
'by him in the Senate on January 31,\n'
'1908. had been prepared by the At\n'
'torney General and that his “Interest\n'
'in the matter had been first aroused\n'
'by a desire to purchase some of the\n'
'timber land.”\n'
'Mr. Bonaparte also replies to Sen\n'
"ator Tillman's remarks made in the\n"
'Senate last February that he had not\n'
'"bought any land anywhere in the west\n'
'or undertaken to buy any.”\n'
'The full text of the Attorney Gen\n'
"eral's statement is as follows:\n"
'“January 12, 1909.\n'
'"There are two passages in the re\n'
'marks of Senator Tillman published\n'
"in today's Congressional Record, which\n"
'demand notice from me. He says:\n'
'"It might be well to inquire wheth\n'
'er or not the Attorney General has\n'
'been ordered not to obey the law of\n'
'Congress passed last April—-which I\n'
'will call the Tlllman-Bonaparte law—\n'
'directing suit to be Instituted for the\n'
'recovery of these lands. My culpabil\n'
'ity is of such enormity and magnitude\n'
'in contemplating the purchase of Hill\n'
'acres of land at $2.60 an acre in the\n'
'eyes of this stickler for official recti\n'
'tude in others that it may be found\n'
'that he is determined to block my so\n'
'called nefarious transactions.\n'
'Tillman s Words.\n'
"“ 'The man who announces to Con\n"
'gress that he, Theodore Roosevelt, as\n'
'sumed the right to permit the steel\n'
'trust to absorb Its greatest rival con\n'
'trary to law, would doubtless not hes\n'
'itate to help Ills dear friend, Harrl\n'
'man. In holding 2,000,000 acres of the\n'
'public domain simply because Ben Till\n'
'man has contemplated and wanted to\n'
"buy 1440 acres.'\n"
'“On September 14, 1908, suit was\n'
'brought by the United States of Amer\n'
'ica In the circuit court of the United\n'
'States for the district of Oregon against\n'
'the Oregon and California Railroad\n'
'company, the Southern Pacific com\n'
'pany, the Union Trust company. Indi\n'
'vidually and as trustee; Stephen T.\n'
'Gage, Individually and as trustee, and\n'
'a large number of Individual defend\n'
'ants. The purpose of tills suit Is, In\n'
'substance, to declare and enfore a for\n'
'feiture of the public lands claimed\n'
"by the railroads under Mr. Harrlman's\n"
'control by virtue of the original grant\n'
'to the Oregon and California railroad.\n'
'It has been brought In accordance with\n'
'the directions of the Joint resolution\n'
'to which Senator TUlmon refers was\n'
'Instituted as soon as practicable after\n'
'the passage of the said resolution and\n'
'the fact of Its Institution has been pub\n'
'lished and could have been verified\n'
'by any one, through inquiring at this\n'
'department, for more than four months.\n'
'Interest In Matter.\n'
'"Senator Tillman says In another part\n'
'of his speech, ‘In my conversation with\n'
'the Attorney General In regard to the\n'
'resolution which I Introduced and which\n'
'he himself prepared after we had talked\n'
'over the whole land situation, I distinctly\n'
'remember telling him that my Interest\n'
'in the matter had been first nroused by\n'
'my desire to purchase some of the tim\n'
'ber lands, and that my coming to him was\n'
'due to the fact that I discovered upon\n'
'Investigation that I could not buy It\n'
'through any agency whatsovcr; that I\n'
'could not buy It even by a lawsuit, be\n'
'cause I was advised by very able lawyers\n'
'In the west, among them George Turner\n'
'of Washington, that In attacking the\n'
'holders of these land grants no one would\n'
'have any standing In court except the\n'
"grantor, the government Itself.'\n"
'Visit From Tillman.\n'
'"Senator Tillman called upon me at\n'
'the department of Justice a few days be\n'
'fore the introduction by him of the reso\n'
'lution, which 1 see by the record, he\n'
'presented to the Senate on January 31,\n'
'1908. Our Interview occurred, therefore,\n'
'a little less than three weeks before his\n'
'letter of February 16 to Messrs. Reeder\n'
'ft Watkins. In which he requested them\n'
"'to hold tu rasarve’ for him 'eight of the\n"
"best quarter sections'; and probably a\n"
'little more than three weeks before his\n'
'statement In the Senate that he had not\n'
'‘bought any land Hnywhere In the west, j\n'
'or undertaken to buy any.’ He told me lie j\n'
'wished Information as to the status of the i\n'
'land embraced in these Oregon grants !\n'
'because he had heard so much complaint\n'
'about the conduct of the corporations\n'
'claiming them during his recent journey j\n'
'through the states of the Pacific slope. I\n'
'He criticised, with great severity, the |\n'
'policy of granting the public domain to\n'
'such corporations, and mentioned thnt I\n'
'on some occasion. In discussing a proposed ;\n'
'land grant of this character he had said\n'
'to certain of his colleagues:\n'
'Yields to Demand.\n'
'"You may as well give them what they\n'
'want now: you have given them pretty\n'
'much everything else. He said, according :\n'
"to my recollection, that the lands had '\n"
'become of great value, and many persons\n'
'wished to purchase them, and added that\n'
'he would have been glad to do bo himself\n'
'if he could; but he never told me a word\n'
'of any connection, on his part, with an\n'
'arrangement to acquire some part of these\n'
'lands, nor that he Intended, expected or\n'
'even desired, at that time to make any\n'
"'(CONTDIIJUO OW FAGB M.)\n"
'Tennessee Senate Passes the\n'
'Statewide Bill By Vote\n'
'of 20 to 13\n'
'SCENES Of OISOBDEB\n'
'FOLLOW BALLOTING\n'
'Several Hours of Acrid Debate Precede\n'
'the Vote on Prohibition, But Thia\n'
'Does Not Cause Any Change\n'
'In the Ballot.\n'
'Nashville, January 12.—At 5:02 this aft\n'
'ernoon senate bill number 1. providing for\n'
'the prohibition of the sale of liquor with\n'
'Ing four miles of any school house in\n'
'Tennessee passed its third and final read\n'
'ing in tlie senate. The vote was 20 to 13.\n'
'Senators Baskervilie of Sumner and\n'
'Swab of Claiborne, voted with the 18 who\n'
'have been known as "state-wlders."\n'
'It is expected that the house will pass\n'
'the bill tomorrow.\n'
'Immediately after ihe vote in the senate\n'
'was announced the wildest disorder pre\n'
'vailed, and as soon as a motion to ad\n'
'journ could be put and carried a frantic\n'
"'crowd surrounded Messrs. Holliday and\n"
'Mansfield, floor leaders of the prohibition\n'
'forces, and the celebration took on the\n'
'form of a love feast.\n'
'The debate preceding the passage of the\n'
'measure was replete with sensational in\n'
'cidents, one of which was ex-Oov. John\n'
"I. Cox's speech in defense of his past rec\n"
'ord and his present attitude toward tem\n'
'perance legislation. Another was chargee\n'
'made by Senator Dancy Fort of Mont\n'
'gomery county of intimidation against the\n'
'Rev. Dr. E. E. Folk, whom he termed the\n'
'"high mogul" of the Anti-Saloon league.\n'
'Senator Fort charged that Dr. Folk had\n'
'threatened to ruin him religiously as well\n'
'as politically if he voted against prohibi\n'
'tion, and further charged that Folk was\n'
'attempting to carry out his threat by pub\n'
'lishing in his paper, the Baptist and Re\n'
'flector, an Insinuation to the effect that\n'
'Fort was an infidel.\n'
'Galleries Packed.\n'
'The naileries were packed and jammed\n'
'until it seemed probable that some one\n'
'would be precipitated onto the floor o*\n'
'the senate any minute. The floor wan\n'
'thrown practically open to whomsoever\n'
'desired to enter the chamber, and all of\n'
'the space back of the desks were filled\n'
'with women and politicians. In the front\n'
'row of the gallery sat Mrs. Selena M.\n'
'Holman, state president of the W. C. T.\n'
'U.. and by her side sat Mrs. Florence\n'
'Atkins, another prominent member of that\n'
'organization.\n'
'The spectators were almost all state\n'
'widers. and they were by no means slow\n'
'to express their sentiments. Naught but\n'
'Jeers and hisses greeted the advocates of\n'
'local option, while the wildest cheers were\n'
'sent up at each pause in the speechs for\n'
'state-wide prohibition. Time after time\n'
'Speaker Kinney threatened to clear the\n'
'gallerieB if a more courteous hearing were\n'
'not given the administration senators, but\n'
'it was of little or no avail.\n'
'The entire debate was bitter and\n'
'many strong speeches were made, but\n'
'they were of no effect on the one\n'
'side or the other. Every man pres\n'
'ent had made up ills mind long before\n'
'the session was called to order, and\n'
'the vote taken at 5 o’clock was just\n'
"w'hat It would have been had It been\n"
'taken at 11. Six hours were consumed\n'
'between the time the senate was called\n'
'to order and the moment of adjourn\n'
'ment and nearly all of It was spent\n'
'In consideration of the state-wide\n'
'bill.\n'
'The house was almost forgotten In\n'
'the Importance of the days work In\n'
'the senate, but In that body the Ta\n'
'tum whisky lobby Investigation reso\n'
'lution was tabled. Drs. Chappell and\n'
'Haynes of the Mpthodist church, In a\n'
'resolution Introduced, are called upon\n'
'to appear before the house and sub\n'
'stantiate the charges made by them In\n'
'regard to corrupt Influences being\n'
'brought to bear on state-wide legis\n'
'lation. and If they fall to do that,\n'
'to be haled before the bar of the\n'
'house and show cause why they should\n'
'not he heralded abroad as "common\n'
'slanderers." The house liquor traffic\n'
'committee recommended the state-wide\n'
'bill for passage.\n'
'Charges Against Ministers.\n'
'The resolution regarding the min\n'
"isters' charges was presented by Rep\n"
'resentative Cooper of Shelby county,\n'
'and went over, under the rules. After\n'
'quoting the article from an afternoon\n'
'paper which tells of the ministers’\n'
'allegaTions, It says:\n'
'"Whereas, if said published statement\n'
'correctly quotes the Re,vs. E. B. Chap\n'
'pell and B. F. Haynes this honorable\n'
'body is entitled to know who the rep\n'
'resentative Is who has been seducer!\n'
'and corrupted and tile names of the\n'
'witnesses by whom the charges can\n'
'be proven and the names of the parties\n'
'by whom the charges were made, that\n'
'proper action may be taken by tills\n'
'honorable body in the premises.\n'
'"Therefore, the speaker of the house\n'
'Is hereby authorized and empowered to\n'
'Issue citation to the said E. B. Chap\n'
'pell and B. F. Haynes to appear in\n'
'stanter and make specific charges, giv\n'
'ing the names of tire guilty parties,\n'
'tire seduced and corrupted representa\n'
'tive, the witnesses or witness and tha\n'
'parties who are circulating these fel\n'
'onious charges: that tlie sergeant-at\n'
'arms be directed by the speaker to\n'
'serve this citation at once, command\n'
'ing the said E. B. Chappel and B. F.\n'
'Haynes to appear Instanter at the bar\n'
'of the house and make and file spe\n'
'cific charges against the guilty mem\n'
'ber or members; the names or name\n'
'of the corrupting parties, both men\n'
'and women, and other witnesses they\n'
'may know of, and unless the said E.\n'
'B. Chappell and B. F. Haynes appear\n'
'and file said charges as above required\n'
'Chappell and Haynes obtained their in\n'
'formation—in case of their failure in\n'
'so doing—then that the speaker shall\n'
'Instanter issue a warrant to the ser\n'
'geant-at-arms of the house to arrest\n'
'tile said E. B. Chappell and B. F.\n'
'Haynes and bring them before the bar\n'
'of the house, there to be publicly rep\n'
'rimanded as common slanderers, un\n'
'worthy of belief and decent asso\n'
'ciates.”',
'page': '',
'place': [...],
'place_of_publication': 'Birmingham, Ala.',
'publisher': 'Age-Herald Co.',
'section_label': '',
'sequence': 1,
'start_year': 1902,
'state': [...],
'subject': [...],
'title': 'The Birmingham age-herald. [volume]',
'title_normal': 'birmingham age-herald.',
'type': 'page',
'url': 'https://chroniclingamerica.loc.gov/lccn/sn85038485/1909-01-13/ed-1/seq-1.json'}
dates = [item["date"] for item in data["items"]]
len(dates)
500
dates[:10]
['19090113',
'19120123',
'19170310',
'19060816',
'19090626',
'19050404',
'19120215',
'19080108',
'19060412',
'19110803']
converted_dates = [datetime.strptime(date, '%Y%m%d') for date in dates]
converted_dates[0:10]
[datetime.datetime(1909, 1, 13, 0, 0),
datetime.datetime(1912, 1, 23, 0, 0),
datetime.datetime(1917, 3, 10, 0, 0),
datetime.datetime(1906, 8, 16, 0, 0),
datetime.datetime(1909, 6, 26, 0, 0),
datetime.datetime(1905, 4, 4, 0, 0),
datetime.datetime(1912, 2, 15, 0, 0),
datetime.datetime(1908, 1, 8, 0, 0),
datetime.datetime(1906, 4, 12, 0, 0),
datetime.datetime(1911, 8, 3, 0, 0)]
fig, ax = plt.subplots()
plt.hist(converted_dates, bins=20,edgecolor='black')
# fig.set_size_inches(18.5, 10.5)
# Rotate and right-align the x labels so they don't crowd each other
for label in ax.get_xticklabels(which='major'):
label.set(rotation=30, horizontalalignment='right')
plt.show()