OpenAlex API in Python#
by Michael T. Moen
Please see the following resources for more information on API usage:
Documentation
Terms
Data Reuse
OpenAlex License: The OpenAlex dataset is free under CC0 license.
NOTE: Please see access details and rate limit requests for this API in the official documentation.
These recipe examples were tested on April 8, 2026.
Setup#
Import Libraries#
The following external libraries need to be installed into your environment to run the code examples in this tutorial:
We import the libraries used in this tutorial below:
from collections import Counter
import os
from pprint import pprint
from time import sleep
from dotenv import load_dotenv
import matplotlib.pyplot as plt
import requests
Import API Key#
An API key is required to access the OpenAlex API. Please see the Authentication & Pricing page for instructions on how to obtain one.
We keep our API key in a .env file and use the dotenv library to access it. If you would like to use this method, create a .env file and add the following line to it:
OPENALEX_API_KEY="YOUR-API-KEY-HERE"
load_dotenv()
try:
API_KEY = os.environ["OPENALEX_API_KEY"]
except KeyError:
print("API key not found. Please set 'OPENALEX_API_KEY' in your .env file.")
OpenAlex Snapshot#
OpenAlex also offers a database download that is updated monthly. This option may be more useful than the API when working with larger datasets and when up-to-date data is unimportant.
More information can be found here.
1. Simple Queries#
The OpenAlex API has a works endpoint that can be used to search for works using a query. In this example, we’ll consider several different queries. More information on search queries can be found here.
Simple Title Query#
This first example will search for the term “geodetics”:
BASE_URL = 'https://api.openalex.org/'
endpoint = 'works'
filters = 'title.search:"geodetics"'
params = {
'filter': filters,
'api_key': API_KEY
}
geodetics_data = requests.get(BASE_URL + endpoint, params=params).json()
# Display resulting metadata
geodetics_data['meta']
{'count': 14044,
'db_response_time_ms': 14,
'page': 1,
'per_page': 25,
'groups_count': None,
'cost_usd': 0.001}
The count in the output above tells us how many works have been published by UA authors.
It’s also important to note that the data returned by this API request is just the first page of size 25. That means that in order to obtain the data for all works in data_retrieved['results'], we must page through this data.
Each work obtained in the query will have the following structure:
pprint(geodetics_data['results'][0], depth=1)
{'abstract_inverted_index': None,
'apc_list': None,
'apc_paid': None,
'authorships': [...],
'awards': [],
'best_oa_location': {...},
'biblio': {...},
'citation_normalized_percentile': {...},
'cited_by_count': 894,
'cited_by_percentile_year': {...},
'concepts': [...],
'content_urls': {...},
'corresponding_author_ids': [...],
'corresponding_institution_ids': [],
'countries_distinct_count': 0,
'counts_by_year': [...],
'created_date': '2025-10-10T00:00:00',
'display_name': 'A testing procedure for use in geodetic networks',
'doi': 'https://doi.org/10.54419/t8w4sg',
'funders': [],
'fwci': 0.3898,
'has_content': {...},
'has_fulltext': False,
'id': 'https://openalex.org/W2990798733',
'ids': {...},
'indexed_in': [...],
'institutions': [],
'institutions_distinct_count': 1,
'is_paratext': False,
'is_retracted': False,
'is_xpac': False,
'keywords': [...],
'language': 'en',
'locations': [...],
'locations_count': 2,
'mesh': [],
'open_access': {...},
'primary_location': {...},
'primary_topic': {...},
'publication_date': '1968-01-01',
'publication_year': 1968,
'referenced_works': [],
'referenced_works_count': 0,
'related_works': [...],
'relevance_score': 386.79306,
'sustainable_development_goals': [],
'title': 'A testing procedure for use in geodetic networks',
'topics': [...],
'type': 'book',
'updated_date': '2026-04-04T16:13:02.066488'}
Index Out Query Results#
Now that we’ve obtained some data from the API, we can index out some of data from this query:
# Display the DOI of the second work returned
geodetics_data['results'][2]['doi']
'https://doi.org/10.1002/2014gc005407'
# Display the title of the second work returned
geodetics_data['results'][2]['title']
'A geodetic plate motion and Global Strain Rate Model'
# Display the primary institution of the first author of the second work returned
geodetics_data['results'][2]['authorships'][0]['institutions'][0]
{'id': 'https://openalex.org/I134113660',
'display_name': 'University of Nevada, Reno',
'ror': 'https://ror.org/01keh0577',
'country_code': 'US',
'type': 'education',
'lineage': ['https://openalex.org/I134113660']}
# Display titles of first 10 results
for work in geodetics_data['results'][:10]:
print(work['title'])
A testing procedure for use in geodetic networks
Geodetic Reference System 1980
A geodetic plate motion and Global Strain Rate Model
Geodetic determination of relative plate motion in central California
Effect of annual signals on geodetic velocity
Inertial Navigation Systems with Geodetic Applications
Short Note: A global model of pressure and temperature for geodetic applications
Geodetic Reference System 1980
Geodetic reference system 1980
Density assumptions for converting geodetic glacier volume change to mass change
Query with Boolean Logic#
The API also allows us to use boolean operators AND, OR, and NOT (must be capitalized) when querying for works. This example searches for works whose abstracts contain “simulation” and “chemistry” and not “medicine” or “energy”:
endpoint = 'works'
filters = 'abstract.search:("simulation" AND "chemistry") NOT ("medicine" OR "energy")'
params = {
'filter': filters,
'api_key': API_KEY
}
data = requests.get(BASE_URL + endpoint, params=params).json()
# Display resulting metadata
data['meta']
{'count': 41091,
'db_response_time_ms': 47,
'page': 1,
'per_page': 25,
'groups_count': None,
'cost_usd': 0.001}
2. Retrieve Publications from an Institution#
The OpenAlex API provides several ways to find the works published through an institution. In this tutorial, we’ll look at how to achieve this by searching with an ROR ID and an OpenAlex ID.
Search Using an ROR Identifier#
The OpenAlex API allows us to access the publications from an institution through its ROR ID. To find the ROR ID for an institution, we can search for the institution here.
To see how to programmatically obtain ROR IDs for institutions, please see our Research Organization Registry cookbook tutorials.
In this example, we’ll look at the University of Alabama, which has the ROR identifier of https://ror.org/03xrrjk67.
ua_ror = 'https://ror.org/03xrrjk67'
endpoint = 'works'
filters = f'institutions.ror:{ua_ror}'
params = {
'filter': filters,
'api_key': API_KEY
}
ua_data = requests.get(BASE_URL + endpoint, params=params).json()
# Display length of data and other info
ua_data['meta']
{'count': 67900,
'db_response_time_ms': 74,
'page': 1,
'per_page': 25,
'groups_count': None,
'cost_usd': 0.0001}
Search Using an OpenAlex ID#
To find the OpenAlex ID of an institution, we’ll first perform an institution search:
endpoint = 'institutions'
search = 'University of Alabama'
params = {
'search': search,
'api_key': API_KEY
}
institutions_search_results = requests.get(BASE_URL + endpoint, params=params).json()
# Display resulting metadata
institutions_search_results['meta']
{'count': 11,
'db_response_time_ms': 33,
'page': 1,
'per_page': 25,
'groups_count': None,
'cost_usd': 0.001}
# Print structure of the first response
pprint(institutions_search_results['results'][0], depth=1)
{'associated_institutions': [...],
'cited_by_count': 15043205,
'country_code': 'US',
'counts_by_year': [...],
'created_date': '2016-06-24T00:00:00',
'display_name': 'University of Alabama at Birmingham',
'display_name_acronyms': [...],
'display_name_alternatives': [...],
'geo': {...},
'homepage_url': 'https://www.uab.edu',
'id': 'https://openalex.org/I32389192',
'ids': {...},
'image_thumbnail_url': 'https://commons.wikimedia.org/w/index.php?title=Special:Redirect/file/UABirmingham%20logo.png&width=300',
'image_url': 'https://commons.wikimedia.org/w/index.php?title=Special:Redirect/file/UABirmingham%20logo.png',
'international': {},
'is_super_system': False,
'lineage': [...],
'relevance_score': 228163.19,
'repositories': [],
'roles': [...],
'ror': 'https://ror.org/008s83205',
'status': 'active',
'summary_stats': {...},
'topic_share': [...],
'topics': [...],
'type': 'education',
'type_id': 'https://openalex.org/institution-types/education',
'updated_date': '2026-04-08T06:00:36',
'works_api_url': 'https://api.openalex.org/works?filter=institutions.id:I32389192',
'works_count': 150339}
This query returned several universities related to the “University of Alabama”:
# Print the top 10 results
for institution in institutions_search_results['results']:
print(f"{institution['display_name']}: {institution['id']}")
University of Alabama at Birmingham: https://openalex.org/I32389192
University of Alabama: https://openalex.org/I17301866
University of Alabama in Huntsville: https://openalex.org/I82495205
University of Alabama at Birmingham Hospital: https://openalex.org/I1335695989
University of South Alabama: https://openalex.org/I83809506
University of Alabama System: https://openalex.org/I2800507078
University of South Alabama Medical Center: https://openalex.org/I4210151789
University of North Alabama: https://openalex.org/I12970578
University of West Alabama: https://openalex.org/I68631920
UAB Medicine: https://openalex.org/I4390039250
Amridge University: https://openalex.org/I2800517358
As we can see above, the OpenAlex ID for the University of Alabama is “https://openalex.org/I17301866” or just “I17301866”
ua_openalex_id = 'I17301866'
endpoint = 'works'
filters = f'institutions.id:{ua_openalex_id}'
params = {
'filter': filters,
'api_key': API_KEY
}
ua_data = requests.get(BASE_URL + endpoint, params=params).json()
# Display resulting metadata
ua_data['meta']
{'count': 67900,
'db_response_time_ms': 69,
'page': 1,
'per_page': 25,
'groups_count': None,
'cost_usd': 0.0001}
As we can see from the count in the metadata, these two approaches found the same number of publications.
3. Page through the Results of a Query#
In the examples above, we have only retrieved the first page of results for a query. If we wish to obtain all of the data for an institution, we must page through the results. Paging is used in the example below to obtain all of the publications by UA in the OpenAlex database:
# Parameters for obtaining UA publications
endpoint = 'works'
filters = 'institutions.id:I17301866'
# The cursor to the next page is given in the metadata of the response
# To get the first page, we set the cursor parameter to '*'
cursor = '*'
page_size = 200
ua_articles = []
# When the end of the results has been reached, the 'next_cursor' variable will be null
# This while loop iterates through all pages of the results
while cursor is not None:
params = {
'filter': filters,
'cursor': cursor,
'per-page': page_size,
'api_key': API_KEY
}
page_data = requests.get(BASE_URL + endpoint, params=params).json()
# Set cursor to the next page
cursor = page_data['meta']['next_cursor']
# Add results to the ua_articles list
ua_articles.extend(page_data['results'])
# Wait 0.2 seconds between requests to follow OpenAlex's rate limit
sleep(0.2)
# Display number of UA articles in database
len(ua_articles)
67900
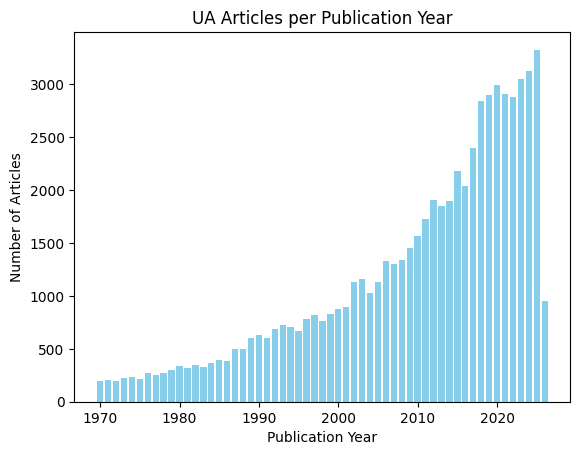
Plot UA Publications by Year#
This example plots the number of UA publications per year from 1970 onward:
# Extract publication years
publication_years = []
for article in ua_articles:
if article['publication_year'] and article['publication_year'] >= 1970:
publication_years.append(article['publication_year'])
# Count occurrences of each publication year
year_counts = Counter(publication_years)
# Plot data
years = list(year_counts.keys())
counts = list(year_counts.values())
plt.bar(years, counts, color='skyblue')
plt.xlabel('Publication Year')
plt.ylabel('Number of Articles')
plt.title('UA Articles per Publication Year')
plt.show()
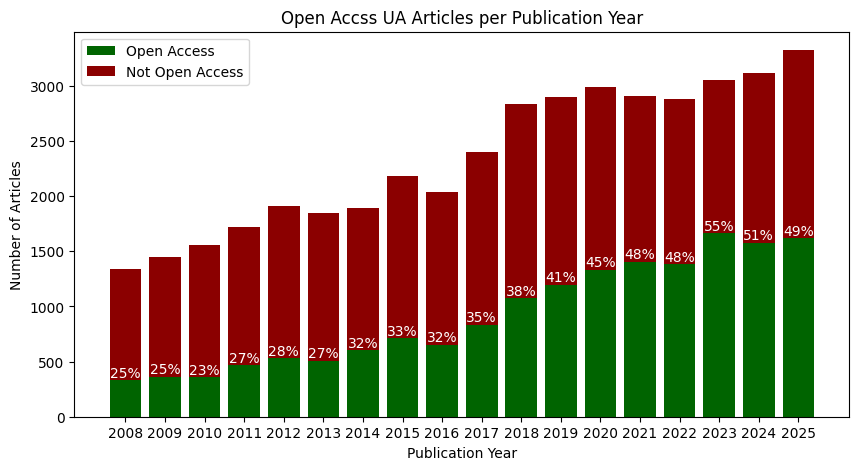
Plot Open Access UA Publications#
Inspired by: https://github.com/ourresearch/openalex-api-tutorials/blob/main/notebooks/institutions/oa-percentage.ipynb
This example plots the prevalence open access in UA articles from 2000 onward:
# Extract publication years and 'is_open' values
year_oa = [(art['publication_year'], art['open_access']['is_oa']) for art in ua_articles]
# Filter to include only years after 1999
filtered_data = [
(year, is_open)
for year, is_open in year_oa
if year and 2008 <= year <= 2025
]
# Count occurrences of (year, is_open)
count_per_year_is_open = Counter(filtered_data)
# Plot data
years = sorted(set(year for year, _ in filtered_data))
open_access_counts = [count_per_year_is_open[(year, True)] for year in years]
not_open_access_counts = [count_per_year_is_open[(year, False)] for year in years]
# Compute and add percentages
percent_oa = []
for oa,not_oa in zip(open_access_counts,not_open_access_counts):
percent_oa.append(round((oa/(oa + not_oa)*100)))
# Plot with percentage labels
fig, ax = plt.subplots(figsize=(10, 5))
bars = plt.bar(years, open_access_counts, color='darkgreen', label='Open Access')
# Add labels above bars
for bar, percent in zip(bars, percent_oa):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width() / 2, height, f'{percent}%', ha='center', va='bottom',
color='white', fontsize=10)
plt.bar(years, not_open_access_counts, bottom=open_access_counts, color='darkred',
label='Not Open Access')
plt.xlabel('Publication Year')
plt.ylabel('Number of Articles')
plt.title('Open Accss UA Articles per Publication Year')
plt.legend(loc='upper left')
ax.set_xticks(years)
plt.show()