Library of Congress API in Python#
By Michael T. Moen, Avery Fernandez, and Jay Crawford
The Library of Congress (loc.gov) API provides programmatic access to Chronicling America, a vast collection of historic American newspapers, and other resources, enabling researchers and developers to search, retrieve, and analyze digitized newspaper pages and metadata.
Please see the following resources for more information on API usage:
Documentation
Terms
Data Reuse
NOTE: Please see access details and rate limit requests for this API in the official documentation.
These recipe examples were tested on March 4, 2026.
Attribution: We thank Professor Jessica Robertson (UA Libraries, Hoole Special Collections) for helpful discussions. All data was collected from the Library of Congress, Chronicling America: Historic American Newspapers site, using the API.
Note that the University of Alabama Libraries has contributed content to Chronicling America: https://www.loc.gov/ndnp/awards/
Setup#
The following external libraries need to be installed into your environment to run the code examples in this tutorial:
We import the libraries used in this tutorial below:
import calendar
from collections import Counter
from datetime import datetime
import io
from pprint import pprint
import re
from time import sleep
import matplotlib.pyplot as plt
from pypdf import PdfWriter
import requests
1. Retrieve Publication Information by LCCN#
A Library of Congress Control Number (LCCN) is a unique ID used to identify records within the Library of Congress. The loc.gov API identifies newspapers and other records using LCCNs. We can query the API once we have the LCCN for the newspaper and even ask for particular issues and editions. For example, the following link lists newspapers published in the state of Alabama, from which the LCCN can be obtained: Chronicling America: Alabama Newspapers.
Here is an example with the Alabama State Intelligencer:
BASE_URL = "https://www.loc.gov/"
endpoint = "item"
lccn = "sn84021903"
params = {
"fo": "json"
}
# Retrieve API response
response = requests.get(f"{BASE_URL}{endpoint}/{lccn}" , params)
# Status code 200 indicates success
response
<Response [200]>
# Extract JSON data from the response
data = response.json()
# Print structure of the response
pprint(data, depth=1)
{'articles_and_essays': None,
'calendar_url': 'https://www.loc.gov/item/sn84021903/?st=calendar',
'cite_this': {...},
'front_pages_url': 'https://www.loc.gov/search/?dl=page&fa=partof:chronicling+america%7Cnumber_page:0000000001%7Cnumber_lccn:sn84021903&fo=json&sb=date&st=gallery',
'holdings_url': 'https://www.loc.gov/item/sn84021903/?st=holdings',
'item': {...},
'more_like_this': [...],
'options': {...},
'related_items': [...],
'resources': [],
'timestamp': 1772649993927,
'title_image_url': 'https://tile.loc.gov/image-services/iiif/service:ndnp:au:batch_au_abernethy_ver01:data:sn84021903:00414187432:1831010101:0004/full/pct:6.25/0/default.jpg#h=369&w=265'}
Indexing into the JSON output allows data to be extracted using key names as demonstrated below:
data["item"]["title"]
'Alabama State Intelligencer (Tuscaloosa, Ala.) 1829-183?'
data["item"]["created_published"]
["Tuscaloosa, Ala. : M'Guire, Henry & M'Guire, 1829-"]
2. Download an Issue as PDF and Full Text#
Moving on to another publication, we can get The Ocala Evening Star newspaper published on July 29th, 1897.
endpoint = "item"
lccn = "sn84027621"
date = "1897-07-29"
edition = "ed-1"
params = {
"fo": "json"
}
response = requests.get(f"{BASE_URL}{endpoint}/{lccn}/{date}/{edition}", params=params)
# Status code 200 indicates success
response
<Response [200]>
Notice from the response below that we could use next_issue or previous_issue to gather batches of issues from the same publication.
# Extract JSON data from the response
data = response.json()
# Print structure of the response
pprint(data, depth=1)
{'articles_and_essays': None,
'calendar_url': 'https://www.loc.gov/item/sn84027621/?st=calendar',
'cite_this': {...},
'item': {...},
'locations': None,
'method': 'mets_filesec',
'more_like_this': [...],
'next_issue': 'https://www.loc.gov/item/sn84027621/1897-07-30/ed-1/?fo=json',
'options': {...},
'previous_issue': 'https://www.loc.gov/item/sn84027621/1897-07-28/ed-1/?fo=json',
'related_items': [...],
'resources': [...],
'timestamp': 1772649995594,
'title_url': 'https://www.loc.gov/item/sn84027621'}
The resources section of the response contains PDF data for each page of the issue. We extract this data below.
# Extract URLs for PDF files from the response
page_urls = [
i["url"]
for category in data["resources"][0]["files"]
for i in category
if i.get("mimetype") == "application/pdf"
]
# Print the list of PDF URLs
page_urls
['https://tile.loc.gov/storage-services/service/ndnp/fu/batch_fu_anderson_ver02/data/sn84027621/00295872287/1897072901/0502.pdf',
'https://tile.loc.gov/storage-services/service/ndnp/fu/batch_fu_anderson_ver02/data/sn84027621/00295872287/1897072901/0503.pdf',
'https://tile.loc.gov/storage-services/service/ndnp/fu/batch_fu_anderson_ver02/data/sn84027621/00295872287/1897072901/0504.pdf',
'https://tile.loc.gov/storage-services/service/ndnp/fu/batch_fu_anderson_ver02/data/sn84027621/00295872287/1897072901/0505.pdf']
Finally, we retrieve the PDF file from each URL and merge them to one PDF using pypdf.
writer = PdfWriter()
for url in page_urls:
# Download the PDF file and append it to the writer
response = requests.get(url)
pdf_stream = io.BytesIO(response.content)
writer.append(pdf_stream)
sleep(1)
# Write the merged PDFs to a new file
writer.write(f"{lccn}_{date}_{edition}.pdf");
Retrieve Full-Text of the First Page#
We can also retrieve the text data retrieved from Optical Character Recognition (OCR) using a similar method.
# Extract URLs for PDF files from the response
full_text_urls = [
i["fulltext_service"]
for category in data["resources"][0]["files"]
for i in category
if i.get("mimetype") == "text/plain"
]
# Print the list of PDF URLs
full_text_urls
['https://tile.loc.gov/text-services/word-coordinates-service?segment=/service/ndnp/fu/batch_fu_anderson_ver02/data/sn84027621/00295872287/1897072901/0502.xml&format=alto_xml&full_text=1',
'https://tile.loc.gov/text-services/word-coordinates-service?segment=/service/ndnp/fu/batch_fu_anderson_ver02/data/sn84027621/00295872287/1897072901/0503.xml&format=alto_xml&full_text=1',
'https://tile.loc.gov/text-services/word-coordinates-service?segment=/service/ndnp/fu/batch_fu_anderson_ver02/data/sn84027621/00295872287/1897072901/0504.xml&format=alto_xml&full_text=1',
'https://tile.loc.gov/text-services/word-coordinates-service?segment=/service/ndnp/fu/batch_fu_anderson_ver02/data/sn84027621/00295872287/1897072901/0505.xml&format=alto_xml&full_text=1']
# Retrieve the data for the first page
response = requests.get(full_text_urls[0])
# Status code 200 indicates success
response
<Response [200]>
# Extract the full text from the response
full_text_key = full_text_urls[0].split("segment=")[1].split("&")[0]
text = response.json()[full_text_key]["full_text"]
# Standardize all whitespace
clean_text = re.sub(r"\s+", " ", text)
# Print first 1000 characters
pprint(clean_text[:1000])
('4 Volume III., Number 37 OCALA, FLORIDA, THURSDAY, JULY 29, 1897 Price 5 '
'Cents A LA A PLAIN STATEMENT. List. Editor Harris and the Tax Let us Fulfill '
'the Law. When our rights in the Marion county delinquent tax list vere '
'threatened by resolutions passed by the county executive commit tee and when '
'we learned that at torneys had been employed by editor F. E. Harris to break '
'up our contract and being assured that a majority of the new board of county '
'commissioners were opposed to us, we were forced to employ council and go '
'into the courts to protect our interests. We were regularly and legally '
'appointed to perform a public service, that of printing the tax sale list '
'and in order, to perform that service, we had to purchase $500 worth of '
'printing material. It would have been great folly in us to have sat down and '
'allowed editor Harris to force this busi ness away from us by unfair and '
'illegal measures after we had gone to so much expense in get ting ready to '
'do it, "Self pre servation is t')
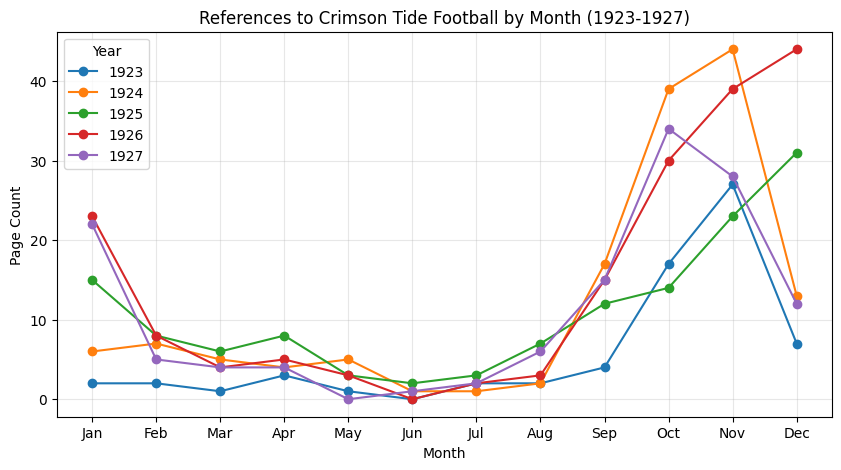
3. Searching for Alabama Football from the Mid 1920s#
In this example, we use the collections endpoint with the chronicling-america collection to search Chronicling America for a specific search phrase. We use the parameters below to achieve this:
searchType: This must be specified asadvancedto use many of the filters in this example.dl: The display level of the results, which can be eitherall,issue, orpage.qs: The search query. In this example, we search for pages with “University of Alabama” and “Football” as search queries.ops: The search operation.PHRASEindicates that we want an exact match for the first search phrase provided inqsandANDindicates that we want all words from the second search phrase included.location_state: Specifies a U.S. state of origin for results.start_dateandend_date: Limits for publication dates of queried pages.c: The number of results to return in each page of the query. This is 40 by default and can range anywhere from 1 to 1000.sp: The page number of the response.
endpoint = "collections/chronicling-america/"
params = {
"searchType": "advanced",
"dl": "page",
"qs": "Crimson Tide!Football",
"ops": "PHRASE!AND",
"location_state": "Alabama",
"start_date": "1923-01-01",
"end_date": "1927-12-31",
"c": 1000,
"sp": 1,
"fo": "json"
}
response = requests.get(f"{BASE_URL}{endpoint}", params=params)
# Extract JSON data from the response
data = response.json()
# Print number of results returned
len(data["results"])
653
# Create a list of dates from each item record
dates = [item["date"] for item in data["results"]]
# Show first 10 dates returned
dates[:10]
['1927-11-09',
'1926-12-19',
'1926-12-23',
'1927-09-24',
'1924-10-29',
'1926-01-01',
'1927-12-09',
'1926-12-08',
'1926-10-30',
'1923-11-27']
# Convert date strings to datetime objects
dates = [datetime.strptime(date, "%Y-%m-%d") for date in dates]
# Count occurrences per (year, month)
year_month_counts = Counter((d.year, d.month) for d in dates)
years = sorted({d.year for d in dates})
months = range(1, 13)
month_labels = [calendar.month_abbr[m] for m in months]
plt.figure(figsize=(10, 5))
for year in years:
counts = [
year_month_counts.get((year, month), 0)
for month in months
]
plt.plot(month_labels, counts, marker='o', label=str(year))
plt.title("References to Crimson Tide Football by Month (1923-1927)")
plt.xlabel("Month")
plt.ylabel("Page Count")
plt.legend(title="Year")
plt.grid(alpha=0.3)
plt.show()
4. Mentions of Keywords in the Birmingham Age-Herald#
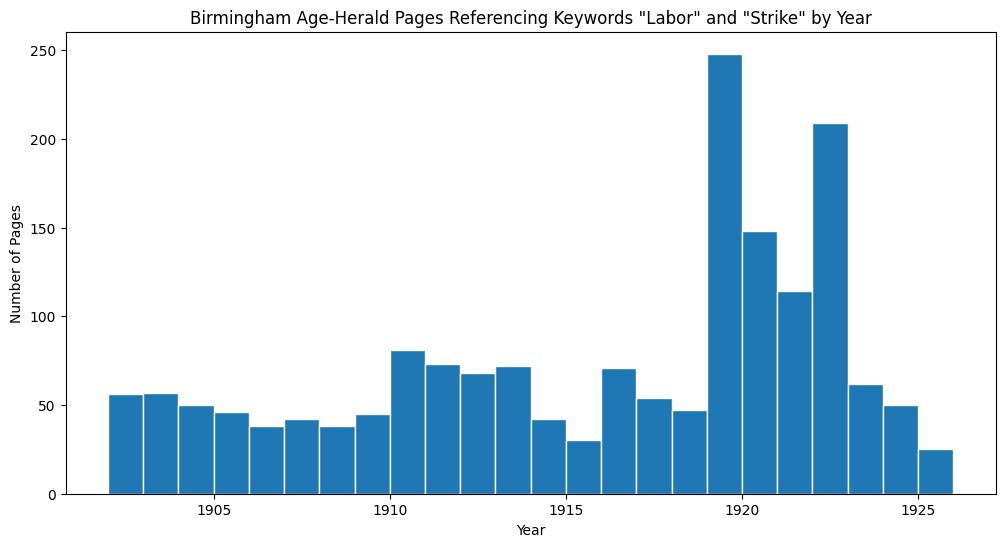
In this example, we search each page of the Birmingham Age-Herald newspapers from the year 1902 to 1926 and for pages that contain keywords “labor” and “strike” within 10 words of each other.
endpoint = "collections/chronicling-america/"
lccn = "sn85038485" # LCCN for the Birmingham Age-Herald
params = {
"searchType": "advanced",
"dl": "page",
"qs": "labor strike", # The search terms
"ops": "~10", # Instances of the search terms above being within 10 words of each other
"location_state" : "Alabama",
"start_date": "1902-01-01",
"end_date": "1926-12-31",
"c": 160,
"fa": f"number_lccn:{lccn}",
"fo": "json"
}
response = requests.get(f"{BASE_URL}{endpoint}", params=params)
# Extract data from response
data = response.json()
# Print total number of results
data["pagination"]["of"]
1766
Page Through Results#
Above, we queried for 160 records (denoted by the c parameter), but we see that the total number of results is greater than 1000. To retrieve all the records from this query, we can page through the results:
# Create data structure to store response data
bham_strike = data["results"]
# Get URL for pagination
next_url = data["pagination"]["next"]
# Page through results
while next_url:
response = requests.get(next_url)
data = response.json()
bham_strike.extend(data["results"])
next_url = data["pagination"]["next"]
sleep(4)
# Print number of results
len(bham_strike)
1766
Plot Results#
# Convert dates to datetime objects
dates = [datetime.strptime(item["date"], '%Y-%m-%d') for item in bham_strike]
# Set up binning by year
min_year = min(d.year for d in dates)
max_year = max(d.year for d in dates)
bins = list(range(min_year, max_year + 2))
fig, ax = plt.subplots(figsize=(12, 6))
ax.hist([d.year for d in dates], bins=bins, edgecolor="white")
plt.title("Birmingham Age-Herald Pages Referencing Keywords \"Labor\" and \"Strike\" by Year")
plt.xlabel("Year")
plt.ylabel("Number of Pages")
plt.show()